Text focused APIs utilizing generative large language models (LLMs)
MARCIE API (2025-08-18T18:01:56Z)
Lets documents, content and metadata be stored in MARCIE for further API processing. To get this data into the MARCIE store, document decomposition and ingestion, as well as manual document/content submission APIs can be used. Once populated, application APIs provide semantic/syntactic analysis, semantic search and content related querying to be executed at scale. See APPS from the navigation panel for more details.
Content is submitted to endpoints with associated control attributes and results are synchronously returned. Primary examples of these APIs include: content comparison, enrichment, transformation, and analysis (spellcheck, grammar, sentiment, readability). See DOCUMENT and CONTENT from the navigation panel for more details. In this scenario, content is not stored or persisted. 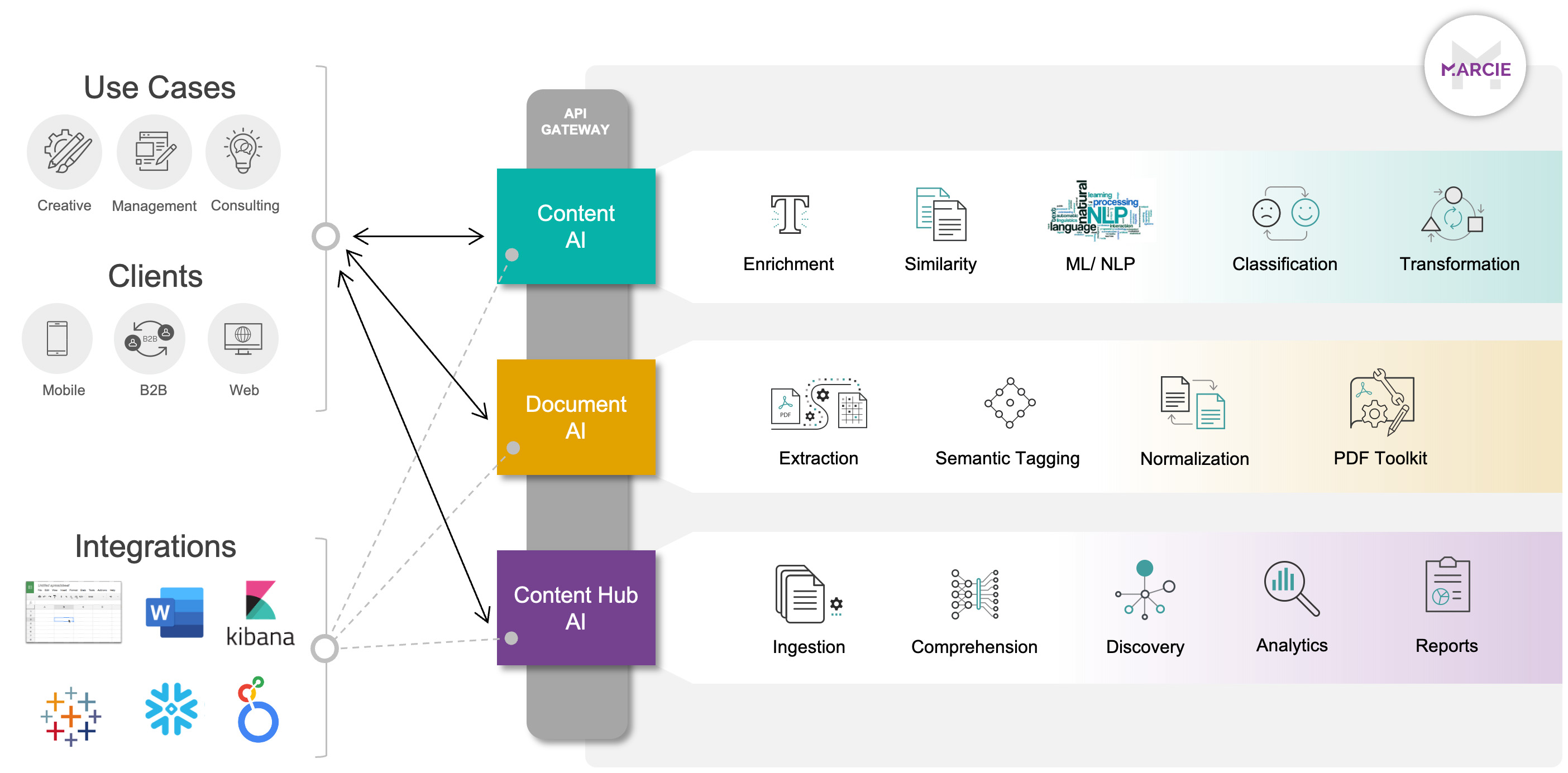
Download OpenAPI description
Overview
MARCIE Support
Languages
Servers
Mock server
https://marcie.redocly.app/_mock/openapi/
https://w1waoh1clk.execute-api.us-east-1.amazonaws.com/{basePath}/
Bodyapplication/jsonrequired
The syntactic similarity algorithms exclusively focus on the representational features of text. The most dominant of these features is the set of tokens (character and words) being used. Different syntactic similarity algorithms exploit these features differently to provide a measure of similarity between an input text pair. The similarity is measured based on a scale of 0 to 1, where 1 represents the best possible match, and 0 indicates the no match scenario. In addition the base algorithms, we also utilize the approach of character and/or word based shingles to add context for increasing the similarity accuracy. The following syntactic similarity algorithms are supported:
- syn.cosine-with-shingles: This represents the combination of applying character-based shingles to the classic cosine similarity algorithm.
- syn.sorensen_dice-shingles: This represents the combination of applying character-based shingles to the classic Sørensen–Dice coefficient algorithm.
- syn.jw-shingles: This represents the combination of applying character-based shingles to the classic Jaro–Winkler algorithm that is similar in nature to edit distance based measures.
- syn.cosine-word: This represents the combination of applying word-based shingles to the classic cosine similarity algorithm. Compared to the syn.cosine-with-shingles, this algorithm will produce less false positives for larger text pieces.
- syn.simple: A Semantax proprietary algorithm that is optimized for comparison speed and accuracy. It is based on the cosine similarity algorithm and it combines both character and word based shingles.
- syn.weighted-word: A Semantax proprietary algorithm that is optimized for comparison speed and accuracy. It is based on the classic [Jaro–Winkler] algorithm. Both character and word based shingles are combined in a weighted capacity to increase the impact of term-frequency.
- syn.sentence: A Semantax proprietary algorithm derived from the classic cosine similarity algorithm. The main feature of this algorithm is the inclusion of NLP (natural language processing) primitives for higher accuracy of similarity comparisons. NLP processing includes lemmatization/stemming, term normalization etc. This algorithm is best suited for a single sentence, or a couple of short sentences as input.
- syn.paragraph: A Semantax proprietary algorithm that extends syn.sentence to compare a pair of input paragraphs (a set of sentences). In addition to the syn.sentence features, this algorithm also includes a weighted Jaccard Similarity score of the overlapping sentences across the input pair.
The semantic similarity algorithms focus on comparing the input text pair based on the main concepts present in the text regardless of the words used to represent these concepts. Roughly speaking it is similar to comparing the meaning of the two sentences independent of the words used. See here for more details. Our semantic similarity algorithms are created using modern deep learning based word embeddings trained on enterprise corpus of sample documents. The models are trained on single sentences, and/or short paragraphs as input, and therefore work best for content size in that range.
All of our semantic similarity algorithms support multi and cross lingual scenarios, where the input text pair can be expressed in any of the supported languages (for example en-en, en-fr, en-es, fr-fr, fr-es etc.). The following semantic similarity algorithms are supported:
- sem.ssm: The default semantic similarity algorithm that offers the best combination of speed and accuracy with an emphasis on english-to-english common language input pairs.
- sem.ssm14: This semantic similarity model is trained on data from government, insurance and banking industry verticals. The model is optimized for speed but provides a good level of over all accuracy.
- sem.ssm20: Similar to sem.ssm14, this model is build on a much larger input corpus.
- sem.ssm28: Builds on the same approach as the previous two models but also includes basic support for higher semantic relationships such as negation.
- sem.ssm30: Similar to ssm28, with better similarity score distribution.
Enum"syn.weighted-word""syn.simple""syn.cosine-with-shingles""syn.sorensen_dice-shingles""syn.cosine-word""syn.jw-shingles""syn.paragraph""syn.sentence""sem.ssm""sem.ssm14"
- Mock server
https://marcie.redocly.app/_mock/openapi/text/similarity
https://w1waoh1clk.execute-api.us-east-1.amazonaws.com/semantex-qa/text/similarity
- curl
- JavaScript
- Node.js
- Python
- Java
- C#
- PHP
- Go
- Ruby
- R
- Payload
curl -i -X POST \
https://marcie.redocly.app/_mock/openapi/text/similarity \
-H 'Content-Type: application/json' \
-H 'x-api-key: YOUR_API_KEY_HERE' \
-d '{
"text1": "how are you",
"lang1": "en",
"text2": "how old are you",
"lang2": "en",
"algo": "syn.cosine-word"
}'Response
application/json
{ "status": { "success": true, "code": 200 }, "result": { "text1": "string", "text2": "string", "score": 1, "prediction": { … } } }
Enrichments/Classification
Text enrichment APIs offer various enrichment functions that take the raw text as its input and provides a specific enrichment/feature corresponding to the input text. An enrichment function is idempotent and its output is determined by the input text and the underlying predictive (deep learning based) linguistic model. Some examples of these include text based sentiment, readability calculation etc. Most of the underlying methods can be used either using a "GET" or a "POST" HTTP method. For smaller text, the GET method offers better performance and allows for network optimizations such as caching.
Operations